Celery Executor¶
注意
從 Airflow 2.7.0 版本開始,您需要安裝 celery provider 包才能使用此執行器。這可以透過安裝 apache-airflow-providers-celery>=3.3.0 或透過安裝帶有 celery extra 的 Airflow 來完成:pip install 'apache-airflow[celery]'。
CeleryExecutor 是您可以擴充套件 worker 數量的方式之一。為了使其工作,您需要設定一個 Celery 後端(RabbitMQ、Redis、Redis Sentinel…),安裝所需的依賴項(例如 librabbitmq、redis…),並修改 airflow.cfg,將 executor 引數指向 CeleryExecutor 並提供相關的 Celery 設定。
有關設定 Celery broker 的更多資訊,請參閱詳細的Celery 相關文件。
Celery Executor 的配置引數可以在 Celery provider 的配置參考中找到。
以下是您的 worker 的幾個強制性要求
需要安裝
airflow,並且 CLI 需要在 path 中Airflow 配置設定在叢集中應保持一致
在 worker 上執行的 Operator 需要在該上下文中滿足其依賴項。例如,如果您使用
HiveOperator,則需要在該機器上安裝 Hive CLI;或者如果您使用MySqlOperator,則需要以某種方式在PYTHONPATH中提供所需的 Python 庫worker 需要能夠訪問其
DAGS_FOLDER,並且您需要透過自己的方式同步檔案系統。一種常見的設定是將您的DAGS_FOLDER儲存在 Git 倉庫中,並使用 Chef、Puppet、Ansible 或您用於在環境中配置機器的任何工具在機器之間同步。如果您的所有機器都有一個公共掛載點,將您的管道檔案共享在那裡也應該可以工作
要啟動一個 worker,您需要設定 Airflow 並啟動 worker 子命令
airflow celery worker
您的 worker 一旦任務被髮送到其方向,就應該開始接收任務。要在機器上停止正在執行的 worker,您可以使用
airflow celery stop
它將嘗試透過向主 Celery 程序傳送 SIGTERM 訊號來優雅地停止 worker,這與 Celery 文件推薦的一樣。
請注意,您還可以執行 Celery Flower(一個構建在 Celery 之上的 web UI)來監控您的 worker。您可以使用快捷命令啟動一個 Flower web 伺服器
airflow celery flower
請注意,您必須已在系統上安裝了 flower python 庫。推薦的方法是安裝 airflow celery bundle。
pip install 'apache-airflow[celery]'
一些注意事項
確保使用資料庫支援的結果後端
確保在
[celery_broker_transport_options]中設定一個可見性超時 (visibility timeout),該超時超過您執行時間最長任務的 ETA如果您使用 Redis Sentinel 作為 broker 並且 Redis 伺服器受密碼保護,請確保在
[celery_broker_transport_options]部分指定 Redis 伺服器的密碼確保在
[worker_umask]中設定 umask 以設定 worker 新建立檔案的許可權。任務會消耗資源。確保您的 worker 有足夠的資源來執行
worker_concurrency任務佇列名稱限制為 256 個字元,但每個 broker 後端可能有自己的限制
有關 Python 和 Airflow 如何管理模組的詳細資訊,請參閱模組管理。
架構¶
Airflow 由幾個元件組成
Workers - 執行分配的任務
Scheduler - 負責將必要的任務新增到佇列中
Web server - HTTP 伺服器提供訪問 DAG/任務狀態資訊的功能
Database - 包含任務、DAG、變數、連線等的狀態資訊
Celery - 佇列機制
請注意,Celery 的佇列由兩個元件組成
Broker - 儲存待執行的命令
Result backend - 儲存已完成命令的狀態
元件在許多地方相互通訊
[1] Web server –> Workers - 獲取任務執行日誌
[2] Web server –> DAG files - 揭示 DAG 結構
[3] Web server –> Database - 獲取任務狀態
[4] Workers –> DAG files - 揭示 DAG 結構並執行任務
[5] Workers –> Database - 獲取並存儲有關連線配置、變數和 XCOM 的資訊。
[6] Workers –> Celery’s result backend - 儲存任務狀態
[7] Workers –> Celery’s broker - 儲存待執行的命令
[8] Scheduler –> DAG files - 揭示 DAG 結構並執行任務
[9] Scheduler –> Database - 儲存 DAG 執行和相關任務
[10] Scheduler –> Celery’s result backend - 獲取有關已完成任務狀態的資訊
[11] Scheduler –> Celery’s broker - 將命令放入待執行佇列
任務執行過程¶
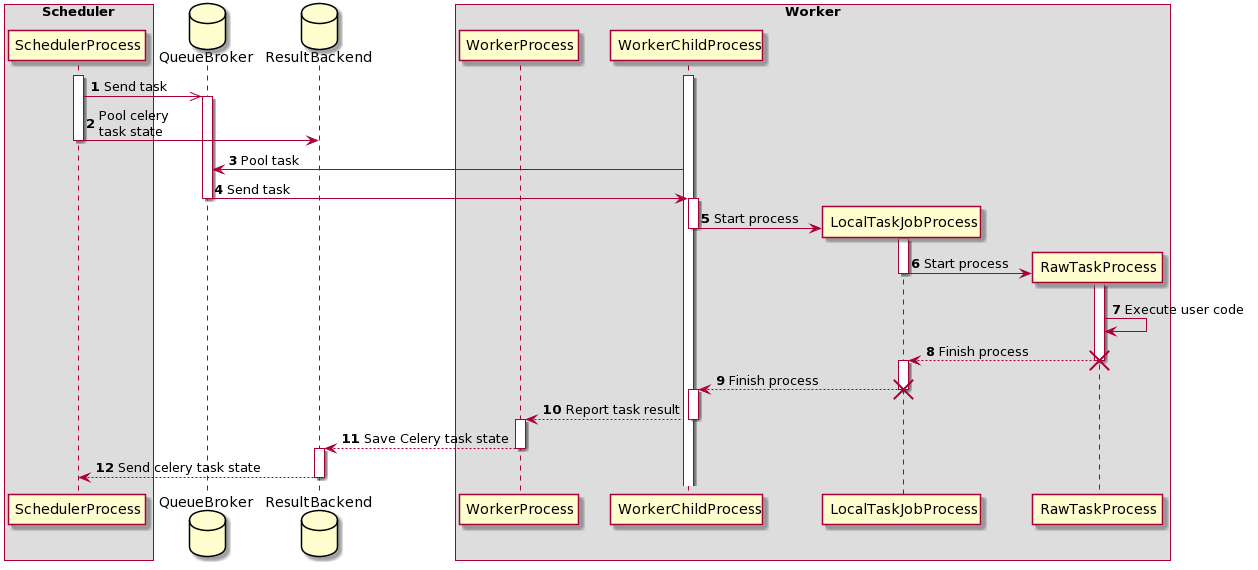
時序圖 - 任務執行過程¶
最初,有兩個程序正在執行
SchedulerProcess - 處理任務並使用 CeleryExecutor 執行
WorkerProcess - 監視佇列等待新任務出現
WorkerChildProcess - 等待新任務
也有兩個資料庫可用
QueueBroker
ResultBackend
在此過程中,建立了兩個程序
LocalTaskJobProcess - 其邏輯由 LocalTaskJob 描述。它監視 RawTaskProcess。新程序使用 TaskRunner 啟動。
RawTaskProcess - 它是包含使用者程式碼的程序,例如
execute()。
execute_command()。它建立一個新程序 - LocalTaskJobProcess。LocalTaskJob 類描述。它使用 TaskRunner 啟動新程序。佇列¶
使用 CeleryExecutor 時,可以指定將任務傳送到的 Celery 佇列。queue 是 BaseOperator 的一個屬性,因此任何任務都可以分配給任何佇列。環境的預設佇列在 airflow.cfg 的 operators -> default_queue 中定義。這定義了未指定時任務被分配到的佇列,以及 Airflow worker 啟動時監聽的佇列。
Worker 可以監聽一個或多個任務佇列。當 worker 啟動時(使用命令 airflow celery worker),可以指定一組以逗號分隔的佇列名稱(無空格)(例如 airflow celery worker -q spark,quark)。然後,該 worker 將僅接收分配到指定佇列的任務。
如果您需要專用的 worker,這會很有用,無論從資源角度(例如對於非常輕量級的任務,一個 worker 可以輕鬆處理數千個任務),還是從環境角度(您希望 worker 在 Spark 叢集內部執行,因為它需要非常特定的環境和安全許可權)。